Multi-Generational Memory Consolidation
/ 8 min read
Pretty early on I realized I had a memory explosion problem. As memories accumulated across conversations and backgroud extraction, they became redundant and fragmented. The same information kept getting extracted in slightly different ways. So I added consolidation: merging semantically similar memories into denser, more useful ones.
It worked fine. Then one morning (I think I was in the shower) a question hit me: why was I artificially limiting this?
The initial implementation only allowed one generation of consolidation. A memory could be merged once, and that was it. But that’s not how human memory works. We consolidate memories throughout our entire lives. Childhood events get reframed through adolescent experiences, which get reinterpreted through adult perspective. Our memories evolve.
Why shouldn’t Iris do the same?
The Memory Explosion Problem
When you build a system that extracts memories from conversations, you end up with a lot of memories. And many of them are saying the same thing in slightly different ways.
Here’s a real example. After several conversations, Iris might have these three memories about a user:
- “Uses Laravel for web development"
- "Prefers Laravel over other PHP frameworks"
- "Has been working with Laravel for several years”
That’s three memories taking up context window space for what is essentially one fact: this person is a Laravel developer. Multiply this across dozens of topics, and your carefully constructed context window becomes cluttered with redundant information.
After consolidation, those become a single, richer memory:
“Experienced Laravel developer who has used the framework for several years and prefers it over other PHP frameworks.”
Same information, one-third the space. The quality of responses improves because the LLM doesn’t have to wade through noise to find signal.
Why Simple Consolidation Isn’t Enough
The obvious solution is consolidation: find similar memories and merge them. Those three Laravel memories become one comprehensive fact. Problem solved.
Except… what happens when that consolidated memory later becomes similar to another memory? And then that result needs to be consolidated again?
This is the hidden complexity of simple consolidation. If you only allow one round of merging, you miss opportunities. That consolidated Laravel memory might later relate to a new memory about “enjoys building developer tools,” and together they paint a richer picture of who this person is.
But there’s a risk on the other end too. Human memory loses detail over time. That’s actually a feature, not a bug. We remember the gist, not the transcript. It helps us generalize and avoid cognitive overload. But without some guardrails, this process can go too far. Memories consolidated too many times become over-abstracted to the point of uselessness. What started as “prefers Laravel over other PHP frameworks” becomes “likes programming.” Technically true, but not helpful.
I call this “lossy compression for memories.” Some compression is good. Too much loses the signal entirely. You need a system that allows evolution while knowing when to stop.
How This Actually Works in Practice
Let me show you what multi-generational consolidation looks like with real memories from my own Iris instance.
Generation 0 (original extractions):
- “Uses Laravel for web development"
- "Prefers Laravel over other PHP frameworks"
- "Has been working with Laravel for several years”
After the first consolidation pass, these became:
Generation 1:
- “Experienced Laravel developer who has used the framework for several years and prefers it over other PHP frameworks”
That’s already useful. But a few weeks later, new memories accumulated:
- “Creator of Prism PHP, a Laravel package for LLM integrations"
- "Active in Laravel community, speaks at conferences"
- "Building Iris as a showcase for Prism’s capabilities”
These clustered with the Gen 1 Laravel memory, and after LLM review:
Generation 2:
- “Experienced Laravel developer and open-source contributor who created Prism PHP for LLM integrations. Active in Laravel community including conference speaking. Building Iris to showcase Prism’s capabilities while preferring Laravel over other PHP frameworks.”
See what happened? The memory evolved. It’s not just “TJ uses Laravel” anymore—it’s a richer understanding of my relationship with the technology and why I’m building what I’m building.
Without multi-generational consolidation, those would stay as separate memories taking up valuable context window space.
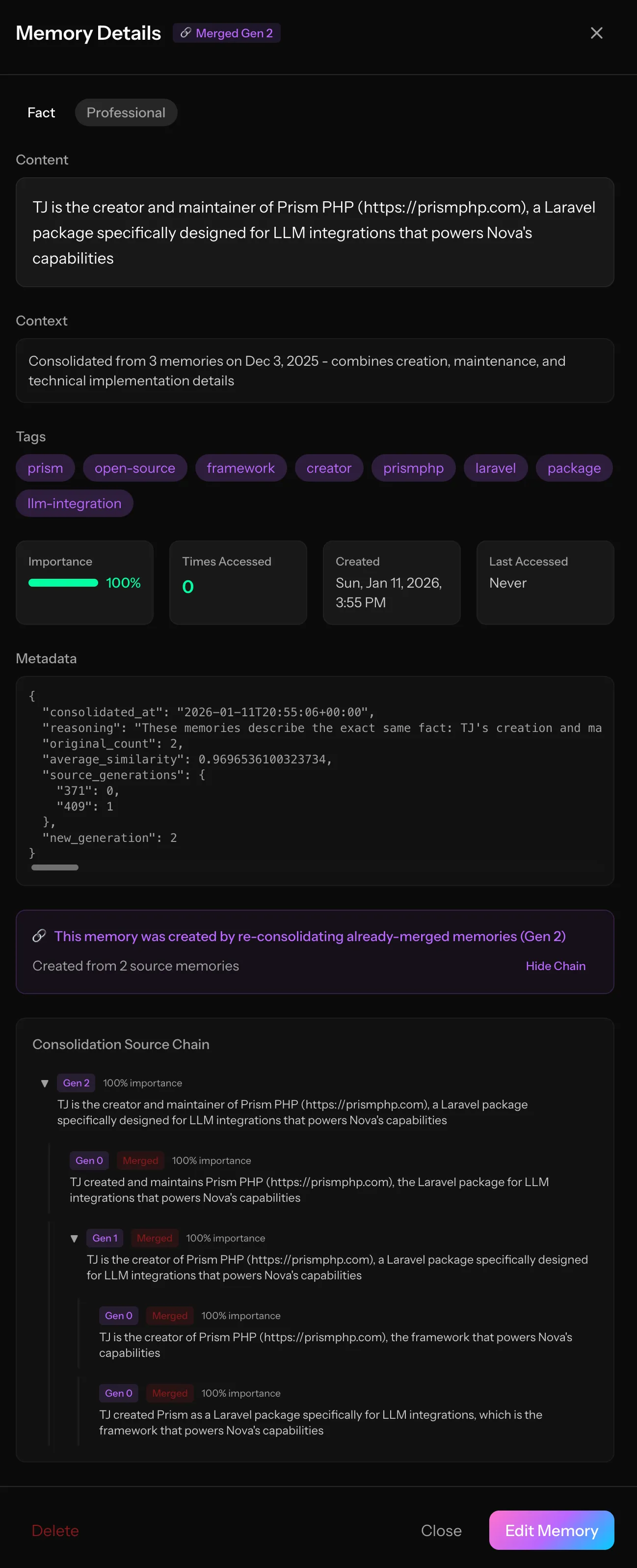
Here’s a real Gen 2 memory from my Iris instance. You can see the entire consolidation lineage, four original memories evolved into this single, richer understanding.
Notice the consolidation chain at the bottom. You can trace the entire lineage.
This visibility matters. When debugging or auditing memory quality, I need to understand not just what a memory says, but how it got there.
The Risk: Over-Consolidation
Here’s the thing though… you can’t just consolidate forever. Without limits, memories abstract into uselessness. Let me show you what I mean.
What happens without generation limits:
- Gen 0: “Prefers Laravel over other PHP frameworks”
- Gen 1: “Experienced Laravel developer”
- Gen 2: “Works with web frameworks”
- Gen 3: “Software developer”
- Gen 4: “Works with computers”
See how it gets progressively less useful? By Gen 4 we’ve lost all the signal. That’s lossy compression taken too far.
This is why I added the generation ceiling. At some point, a memory has been consolidated enough times that it needs to stabilize. I landed on generation 5 as the limit, though this is configurable and I expect to tune it as I learn how the system behaves over time.
Generation Tracking
The solution I landed on was generation tracking. Every memory has a generation number that tracks how many times it’s been through consolidation.
- Generation 0: Original memories extracted from conversations
- Generation 1: First consolidation (merging original memories)
- Generation 2-4: Re-consolidation of already-consolidated memories
- Generation 5+: Configurable ceiling. These memories won’t be consolidated further
The key insight (and I’m super stoked on this) is that memories can now evolve organically. A Gen 1 memory about “prefers TypeScript” might later merge with another Gen 1 memory about “values static typing” to form a richer Gen 2 understanding of the user’s programming philosophy.
This attempts to mirror how human memory works. We consolidate repeatedly, but core memories eventually stabilize into long-term storage.
The Two-Phase Architecture
Running consolidation at scale requires some architectural thought. Making LLM calls for every potential memory pair would be expensive and slow. So I split it into two phases.
Phase 1: Clustering
First, find memories that are semantically similar using vector embeddings. This phase makes no LLM calls. It’s pure database work with PostgreSQL’s vector operations:
$results = DB::select(' SELECT m1.id as id1, m2.id as id2, 1 - (m1.embedding <=> m2.embedding) as similarity FROM memories m1 CROSS JOIN memories m2 WHERE m1.id < m2.id AND 1 - (m1.embedding <=> m2.embedding) >= ? ORDER BY similarity DESC', [$threshold]);This finds all memory pairs with similarity above the threshold (default 0.80). But pairs aren’t enough. We need clusters. If memory A is similar to B, and B is similar to C, they should probably all be considered together.
The clustering algorithm works by building connected groups. Start with the highest-similarity pair and create a cluster. Then iterate through remaining pairs: if either memory in a pair already belongs to a cluster, add the other memory to that same cluster. If neither belongs to a cluster yet, start a new one. This groups transitively related memories together while respecting a maximum cluster size to keep LLM calls manageable.
Phase 2: LLM Review
Each cluster gets dispatched as a separate queued job. The LLM reviews the cluster and decides whether to merge or keep separate:
$response = Prism::structured() ->using(Provider::Anthropic, $model) ->withSchema($schema) ->withSystemPrompt($consolidationPrompt) ->withPrompt('Review these semantically similar memories...') ->asStructured();This separation matters for scalability. Phase 1 processes all users quickly. Phase 2 jobs run in parallel, rate-limited to avoid overwhelming the LLM API. If one cluster fails, it doesn’t affect others.
The LLM as Gatekeeper
Here’s what I think makes this system work: the LLM can reject consolidation.
Just because memories are semantically similar doesn’t mean they should be merged. The LLM evaluates whether consolidation would actually improve things or lose important nuance. Some signals that memories should stay separate:
- They contain genuinely distinct information despite surface similarity
- Each has unique context that matters
- Merging would collapse important specificity
- They represent different time periods (events especially)
For higher-generation memories, the system applies extra scrutiny. These memories have already been through consolidation, so they pack more information density. The bar for merging them again is higher.
Events get special treatment too. A conversation with your manager on Monday and another on Friday are distinct events even if they’re semantically similar. The temporal specificity matters.
Running in Production
Consolidation runs on a schedule:
// Daily incremental at 3:00 AM$schedule->command('iris:consolidate-memories') ->dailyAt('03:00');
// Weekly full sweep on Sundays at 4:00 AM$schedule->command('iris:consolidate-memories --full') ->weeklyOn(Schedule::SUNDAY, '04:00');Daily runs process recent memories (last 3 days). Weekly runs sweep everything to catch memories that didn’t cluster during daily runs. Sometimes new memories create bridges between older ones that weren’t similar enough to cluster before.
There’s a health command to monitor how the system is doing:
Generation ................................................ CountGen 0 (original) ............................................ 623Gen 1 ....................................................... 215Gen 2 ....................................................... 107Gen 3 ......................................................... 4
Total memories .............................................. 949Original memories ........................................... 623Consolidation results ....................................... 326At max generation ............................................. 0Consolidation ratio ....................................... 34.4%Average generation ......................................... 0.46
INFO By Source.
consolidation ............................................... 326extraction .................................................. 319agent ....................................................... 304
Eligible for consolidation .................................. 949Configuration is straightforward:
'consolidation' => [ 'similarity_threshold' => 0.80, 'max_cluster_size' => 5, 'max_generation' => 5, 'jobs_per_minute' => 10,],Higher thresholds (0.85+) are more conservative, so only very similar memories get considered. Lower thresholds merge more aggressively but risk grouping memories that shouldn’t be together. I’ve found 0.80 to be a good balance.
What I’ve Learned
I’m still tuning and evolving multi-generational memory consolidation. The system has processed over 1,100 memories across multiple generations, and the results are pretty noticeable.
But the real win is philosophical. I’m not artificially limiting how the system can evolve anymore. Memories can grow, deepen, and mature—just like human understanding does.
Now excuse me while I go consolidate some of my own memories…